Introducción #
Hasta ahora los ejemplos usando el set de datos de sklearn era con algoritmo de aprendizaje supervisado, es decir, los set de datos tienen características y etiquetas y nos devuelve una predicción. El caso del set de datos de iris tenemos que las características son las mediciones del petalo y cepalo de una planta y las etiquetas a que especie pertenecen.
Pero no siempre vamos a tener datos tan bien construidos, en la mayoria de casos solo se tendrá las características. Para este caso lo que hay que utilizar son algoritmo de aprendizaje no supervisado. Estos algoritmo se especializan en que no necesitan las etiquetas para poder aprender. En el caso del set de datosd e iris solo se le pasarían las mediciones del petalo y cepalo, y con ello que encuentre un patron para poder clasificar bien las flores.
Una librería que nos permite usar este tipo de algoritmos es KMeans. Esta librería permite agrupar los datos en grupos, también llamado K, según las características que tiene.
Como funciona el algoritmo #
La explicación que se habrá aquí pertenece al video Machine Learning episodio 8. KMeans. Se pondrán imagens obtenidas del video para explicar mejor el funcionamiento tal como lo hace en el video.
Imaginemos que tenemos los siguientes datos

En la imagen queda claro que hay dos grupos diferencias pero esto el algoritmo no lo sabe. Entonces al algoritmo hay que indicarle cuantos grupos o cluster queremos que agrupe los datos. En este caso serán 2 o como se ve en las explicaciones: K=2.
Entonces lo que hace el algoritmo es crear un puntos aleatorios llamados centroides:

Entonces lo que hace el algorimto es ver que puntos están mas cercanos a los centroides. Con ello sacará el promedio de los puntos que están más cercanos a los centroides, en la siguiente iteracción se va a mover el centroide al promedio que saco en el paso anterior.
En la siguiente imagen se mostraría que datos estarían más cercanos para cada centroide.
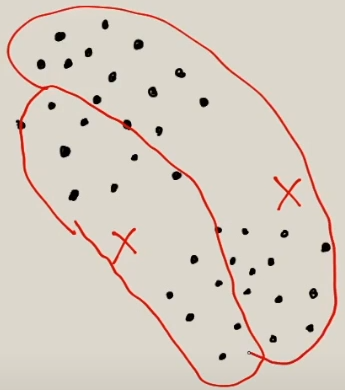
Ahora con el promedio obtenido reajuste los centroides:

Estas iteracciones las va ir repitiendo hasta que los centroides no se muevan o se llege al final de las iteracciones. Lo ideal sería que una ha terminado todas las iteracciones los centroides quedarán en las siguientes posiciones:

Con lo cual los grupos se crearían de la siguiente manera:
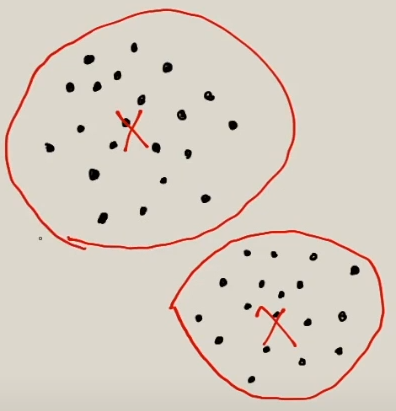
Como los datos no siempre van estar en esta posición ideal hay que tener los datos estén correctos y hacer muchas pruebas de ensaño y error para ir ajustando el número de grupos a clasificar.

Secciones #
Las secciones son las siguientes:
- Ejemplo KMeans
- Ejemplo Kmeans