Introducción #
Ejemplo extraído del video Machine Learning episodio 4. Sobreajuste. Este artículo es un añadido a lo que se comenta brevemente en el artículo de ejemplo sobre arbol de decisiones
En el video indicado se explica perfectamente lo que és, aún así, intento explicarlo a mi manera que es un sobreajuste o overfilling, en ingles. Se usarán pantallazos del video para explicar algunos puntos.
El sobreajuste se produce cuando se entrena el algoritmo ya que intenta generar una formula o ecuación que permite clasificar los datos. El problema viene que al hacer esto sacrifica fiabilidad en las predicciones futuras.
En el ejemplo básico sobre arbol de decisiones se ponía la siguiente imagen de lo que producía el algoritmo sin sobreajuste:
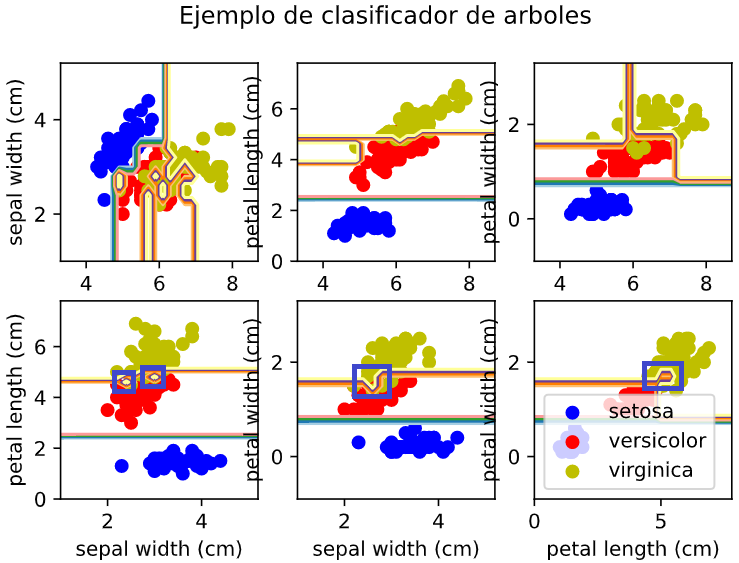
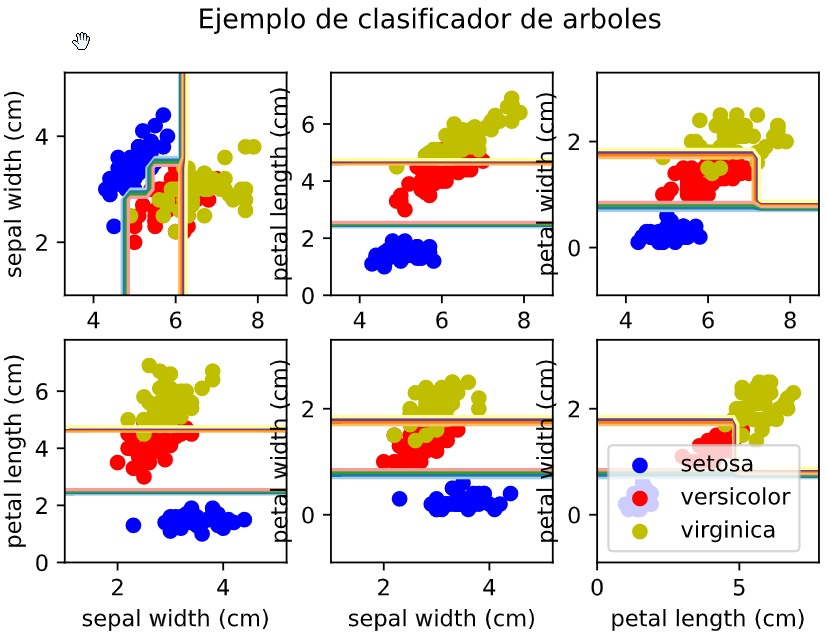
Los recuadros azules marcan el sobreajuste que se produce y una vez ajustado los parámetros del algoritmo ese sobreajuste desaparece:
Explicación #
Imaginemos que tenemos el siguiente set de datos que se tienen que clasificar:
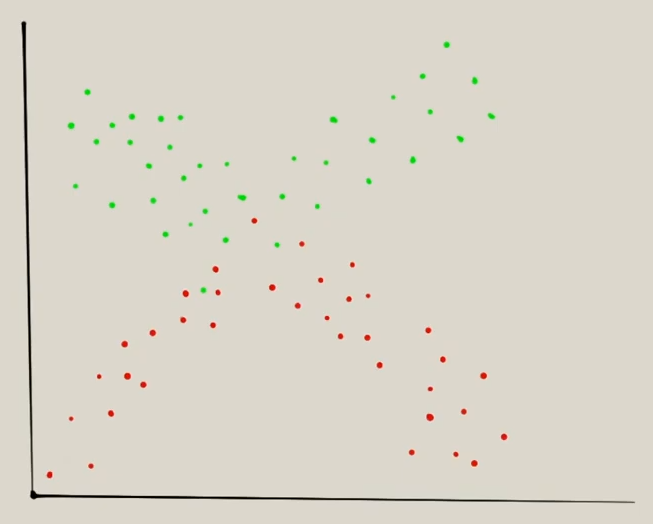
Y queremos que clasifica lo que son rojos y verdes. En un caso normal el algoritmo lo clasificaría de esta manera:
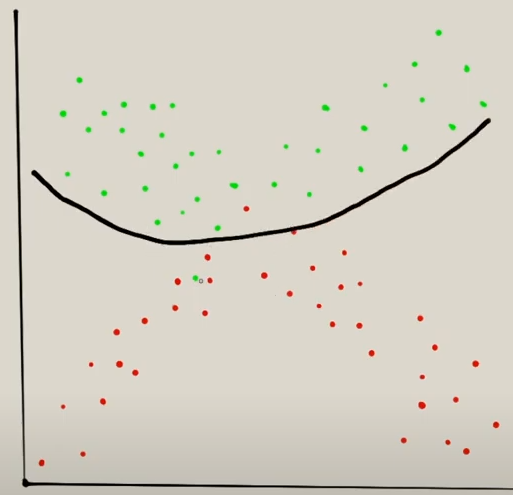
Pero en la imagen hay ciertos puntos verdes y rojos que están mezclados y que con una clasificación normal no se haría correctamente. Lo que ocurre con el algoritmo de clasificación es que intenta hacer esta curva rara:
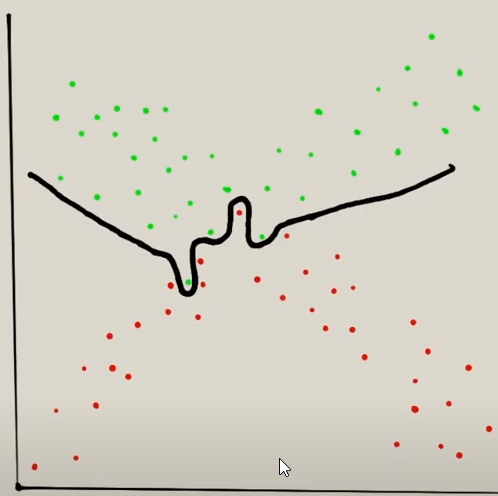
Como se ve intenta clasificarlo todo siguiente la línea. El problema es que si en un futuro viene un valor rojo justo al lado de un verde que este en esas curvas extrañas lo va a clasificar mal.
Con la regresión ocurre lo mismo, en un caso normal intentaría ajuste de la siguiente manera:
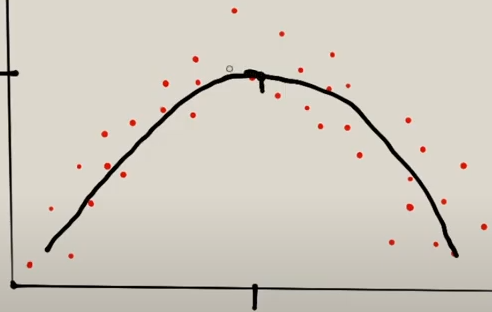
Pero con sobreajuste intentaría hacer todo esto:

El sobreajuste se detecta con la opción score de nuestro algoritmo:
# El resultado con los datos de test son del 94%
arbol.score(X_test,y_test)
Que según el % que devuelva veremos que si el % es 97 para arriba es que esta haciendo sobreajuste. Si el % es más alto más sobreajuste habrá. La solución es ir ajustando los parámetros del modelo o del algoritmo para ir ajustandolos.