Introducción #
Librerias y pawuetes para poder usar el Machine Learning.
Los pasos para instalar las librerías esta explicado en la página de Anaconda.
Tensor Flow #
¿Qué és? #
Según la Wikipedia: TensorFlow es una biblioteca de código abierto para aprendizaje automático a través de un rango de tareas, y desarrollado por Google para satisfacer sus necesidades de sistemas capaces de construir y entrenar redes neuronales para detectar y descifrar patrones y correlaciones, análogos al aprendizaje y razonamiento usados por los humanos.
Instalación #
La librería no esta instalada por defecto, lo más fácil es instalarla a través del anaconda navigator:
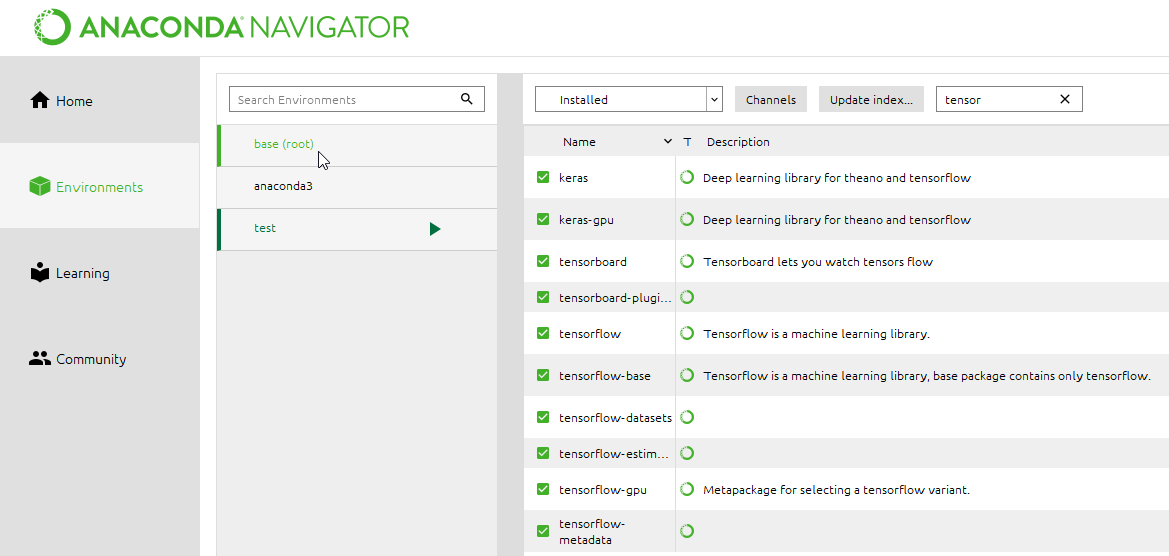
Como es la librería que permite realizar más cosas con Machine Learning se ha instalado tanto versión CPU, como GPU. GPU porque las tarjetas gráficas tienen más procesadores lo que permite hacen calculos más rapidos que si solo se usará la CPU.
En la imagen hay librerías secundarías que se instalan al instalarse la principal.
Numpy #
¿Qué és? #
Según la Wikipedia: NumPy es una extensión de Python, que le agrega mayor soporte para vectores y matrices, constituyendo una biblioteca de funciones matemáticas de alto nivel para operar con esos vectores o matrices.
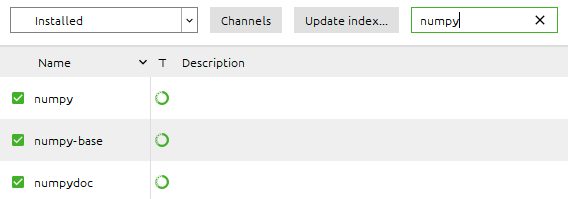
Instalación #
No se instala porque viene incluido con Anaconda:
Scikit learn(Sklearn) #
¿Qué és? #
Según la Wikipedia: Scikit-learn es una biblioteca para aprendizaje automático de software libre para el lenguaje de programación Python.Incluye varios algoritmos de clasificación, regresión y análisis de grupos entre los cuales están máquinas de vectores de soporte, bosques aleatorios, Gradient boosting, K-means y DBSCAN.
Instalación #
Por defecto no se encuentra instalada. En la página que habla Anaconda en el apartado de instalación de paquetes mediante entorno gráfico explica como se hace la instalación.
Graphviz #
¿Qué és? #
Según la Wikipedia: Graphviz es un conjunto de herramientas de software para el diseño de diagramas definido en el lenguaje descriptivo DOT. Fue desarrollado por AT&T Labs y liberado como software libre con licencie tipo Eclipse.
Instalación #
La instalación más sencilla es hacerlo a través de la interface gráfica de Anaconda:
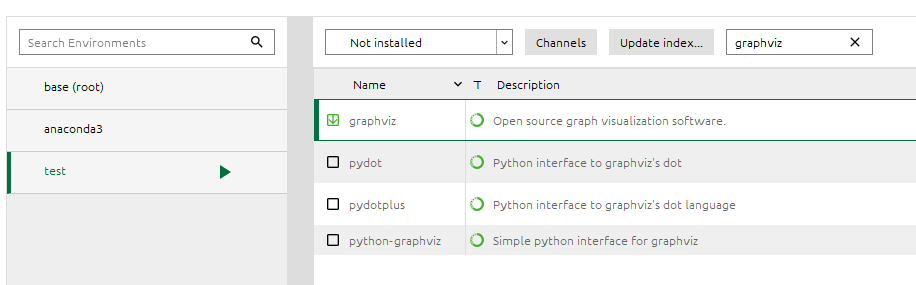
Y el paquete:
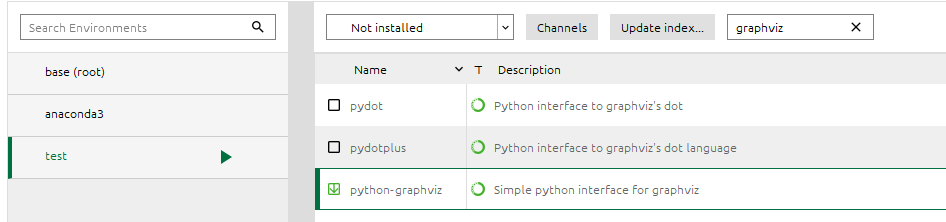
Para que funcione correctamente la libreria.
Matplotlib #
¿Qué és? #
Según la Wikipedia: Matplotlib es una biblioteca para la generación de gráficos a partir de datos contenidos en listas o arrays en el lenguaje de programación Python y su extensión matemática NumPy. Proporciona una API, pylab, diseñada para recordar a la de MATLAB.
Instalación #
Esta libreria ya viene instalada por defecto con Anaconda y no es necesario realizar ningún instalación
SVM (Support Vector Machine / Maquina de vectores de soporte) #
¿Qué és? #
Según la Wikipedia: Las máquinas de vectores de soporte o máquinas de vector soporte (Support Vector Machines, SVMs) son un conjunto de algoritmos de aprendizaje supervisado desarrollados por Vladimir Vapnik y su equipo en los laboratorios AT&T. Estos métodos están propiamente relacionados con problemas de clasificación y regresión. Dado un conjunto de ejemplos de entrenamiento (de muestras) podemos etiquetar las clases y entrenar una SVM para construir un modelo que prediga la clase de una nueva muestra.
Instalación #
Viene incluida en la librería Scikit learn(Sklearn)
NLTK #
¿Qué és? #
Según la Wikipedia: El kit de herramientas de lenguaje natural, o más comúnmente NLTK, es un conjunto de bibliotecas y programas para el procesamiento del lenguaje natural (PLN) simbólico y estadísticos para el lenguaje de programación Python.
Lo que hace el NLTK es eliminar lo que se llaman stop words. stop words son palabras mudas, o que no aportan valor para los algoritmos. Palabras como: en, la, el, una, etc. Son palabras que normalmente los algoritmos de búsqueda suelen ignorar.
Instalación #
La librería no esta instalada por defecto, lo más fácil es instalarla a través del anaconda navigator:
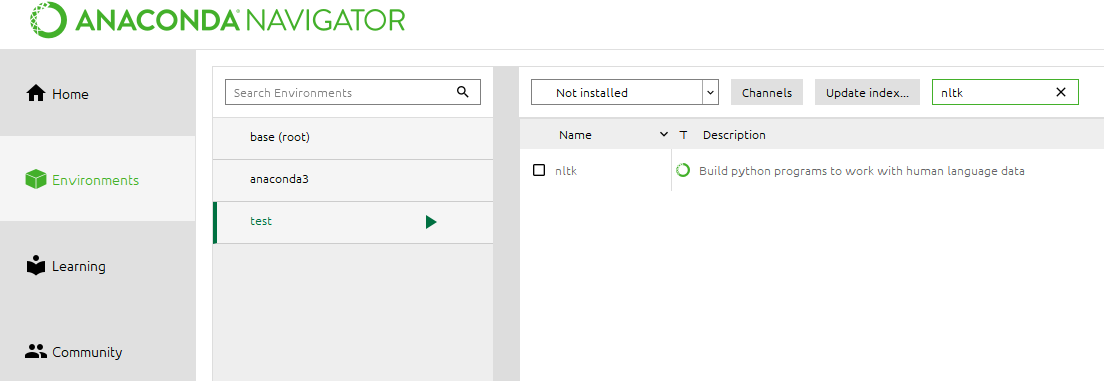
KMeans #
¿Qué és? #
Según la Wikipedia: Es un método de agrupamiento, que tiene como objetivo la partición de un conjunto de n observaciones en k grupos en el que cada observación pertenece al grupo cuyo valor medio es más cercano.
KMens se utiliza en algoritmo de aprendizaje no supervisado.
Instalación #
Viene incluida en la librería Scikit learn(Sklearn)
PCA(Principal component Analysis) #
¿Qué és? #
Según la Wikipedia: En estadística, el análisis de componentes principales (en español ACP, en inglés, PCA) es una técnica utilizada para describir un conjunto de datos en términos de nuevas variables («componentes») no correlacionadas. Los componentes se ordenan por la cantidad de varianza original que describen, por lo que la técnica es útil para reducir la dimensionalidad de un conjunto de datos.
Esta librería se usa para reducir ruido de los datos que se van a procesar y ver los datos de multiples dimension en dos dimensiones para poder analizarlos.
Instalación #
Viene incluida en la librería Scikit learn(Sklearn)
Mglearn #
¿Qué és? #
Realmente no es una librería, es una paquete que tiene funciones de ayuda para el libro Introduction to Machine Learning with Python. En la siguiente dirección esta el detalle de dicho paquete
Instalación #
La instalación hay que hacerla a través del paquete PIP, que ya viene instalado. Para hacerlo ha hacer lo siguiente:
conda activate <nombre entorno>
pip install mglearn
Con esto ya se puede usar la librería o paquete.
Mglearn #
¿Qué és? #
Explicación extráido de Bioinformatics at COMAV
Pandas es un paquete de Python que proporciona estructuras de datos similares a los dataframes de R. Pandas depende de Numpy, la librería que añade un potente tipo matricial a Python. Los principales tipos de datos que pueden representarse con pandas son:
- Datos tabulares con columnas de tipo heterogéneo con etiquetas en columnas y filas.
- Series temporales.
Pandas proporciona herramientas que permiten:
- leer y escribir datos en diferentes formatos: CSV, Microsoft Excel, bases SQL y formato HDF5
- seleccionar y filtrar de manera sencilla tablas de datos en función de posición, valor o etiquetas
- fusionar y unir datos
- transformar datos aplicando funciones tanto en global como por ventanas
- manipulación de series temporales
- hacer gráficas
En pandas existen tres tipos básicos de objetos todos ellos basados a su vez en Numpy:
- Series (listas, 1D),
- DataFrame (tablas, 2D) y
- Panels (tablas 3D).
Instalación #
Viene incluído en la librería Numpy
Mglearn #
¿Qué és? #
Según la Wikipedia: TensorFlow es una biblioteca de código abierto para aprendizaje automático a través de un rango de tareas, y desarrollado por Google para satisfacer sus necesidades de sistemas capaces de construir y entrenar redes neuronales para detectar y descifrar patrones y correlaciones, análogos al aprendizaje y razonamiento usados por los humanos.
Instalación #
Tensor flow no viene instalado por defecto pero justo en el página de Anaconda en la sección de instalación de librerías, se explica como instalar Tensor Flow a modo de ejemplo.
Keras #
¿Qué és? #
Según la Wikipedia: Keras es una biblioteca de Redes Neuronales de Código Abierto escrita en Python. Es capaz de ejecutarse sobre TensorFlow, Microsoft Cognitive Toolkit o Theano. Está especialmente diseñada para posibilitar la experimentación en más o menos poco tiempo con redes de Aprendizaje Profundo. Sus fuertes se centran en ser amigable para el usuario, modular y extensible.
Instalación #
La librería no esta instalada por defecto, lo más fácil es instalarla a través del anaconda navigator:
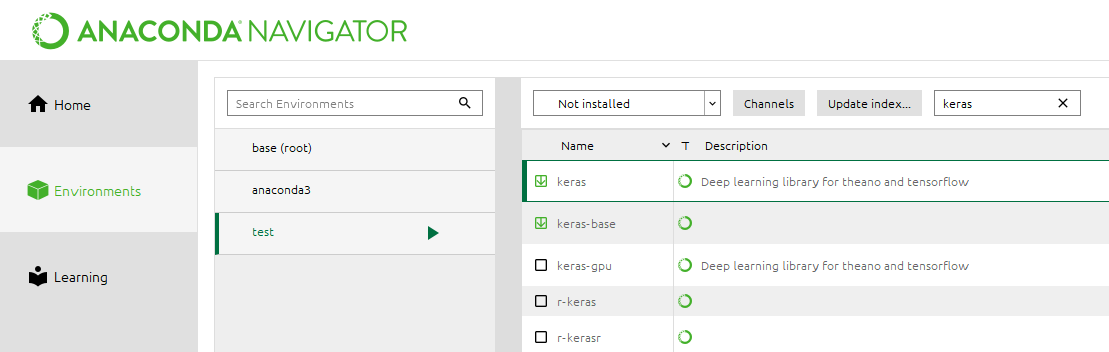
Pylint #
¿Qué és? #
Es una libreria que analiza la calidad del código cuando se desarrolla programas en Python. Más información aquí
Instalación #
La librería no esta instalada por defecto, lo más fácil es instalarla a través del anaconda navigator:

Pillow #
¿Qué és? #
Es una libreria que añade capacidad de procesamiento de imagenes
Instalación #
La librería no esta instalada por defecto, lo más fácil es instalarla a través del anaconda navigator:

ipykernel #
¿Qué és? #
Es una libreria que usa VS Code para poder conectarse a los entornos de anaconda.
Instalación #
La librería no esta instalada por defecto, lo más fácil es instalarla a través del anaconda navigator:
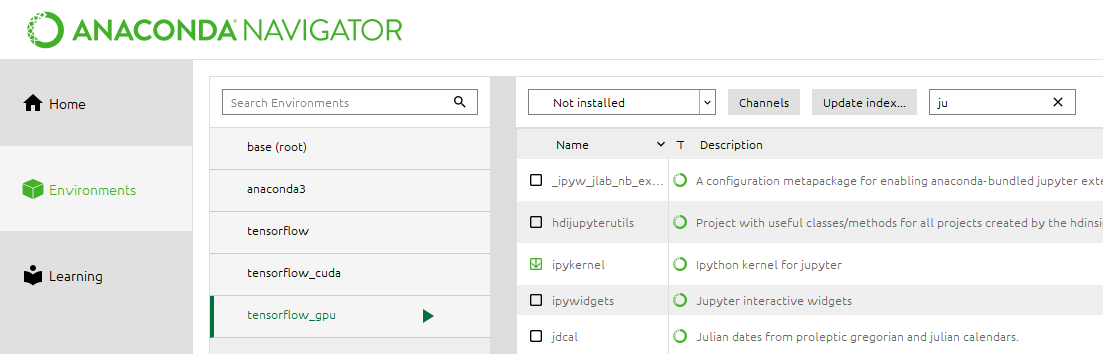
OpenCV #
¿Qué és? #
Según la Wikipedia: es una biblioteca libre de visión artificial originalmente desarrollada por Intel. OpenCV significa Open Computer Vision (Visión Artificial Abierta). Desde que apareció su primera versión alfa en el mes de enero de 1999, se ha utilizado en una gran cantidad de aplicaciones, y hasta 2020 se la sigue mencionando como la biblioteca más popular de visión artificial.1 Detección de movimiento, reconocimiento de objetos, reconstrucción 3D a partir de imágenes, son sólo algunos ejemplos de aplicaciones de OpenCV.
Instalación #
La librería no esta instalada por defecto, lo más fácil es instalarla a través del anaconda navigator:
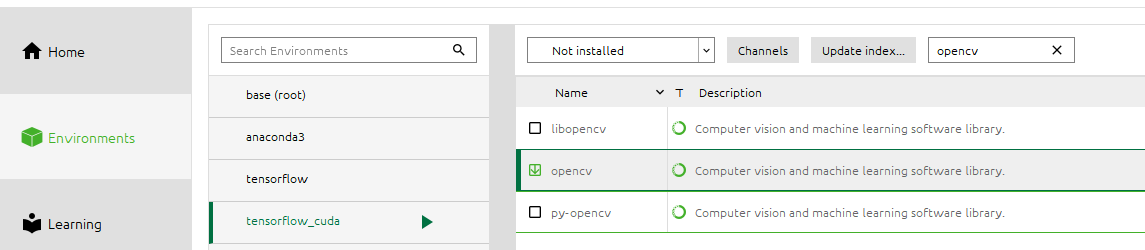
Tesseract #
¿Qué és? #
No es ni librería ni paquete, es un porgrama que se instala en practicamente cualquier sistema operativo y que permite reconocer texto en imagenes. Es un programa que esta bajo licencia Apache v2 con lo que permite ser usado por cualquiera libremente. Actualmente es uno de los mejores OCR open-source.
Instalación #
Como es un programa cuyas versiones van variando lo mejor es consultar dos sitios:
A día 11/08/2020 se ha instalado la versión estable 4.1. Aunque esta disponible la versión 5.0 en versión Alpha
Pytesseract #
¿Qué és? #
Es una librería que encapsula las llamadas a Tesseract simplificando su uso.
Instalación #
La instalación se tiene que realizar a través del instalador de Python, PIP usando el powershell de Anaconda. Los comandos son:
conda activate <entorno>
pip install pytesseract
pip3 install pytesseract
Rope #
¿Qué és? #
Es una librería que permite realizar refactoring en el código
Instalación #
En caso de intentar hacer un refactoring con VSCode sin tenerlo instalado el propio editor te pregunta si lo quieres instalar, haciendo el proceso de manera automática. Si se quiere hacer manualmente hay que hacerlo con el PiP
conda activate <entorno>
pip install rope