Introducción #
Ejemplo extraído de ¿Como funcionan las redes neuronales?. Se pondrán imagens obtenidas del video para explicar mejor el funcionamiento tal como lo hace en el video.
Explicación #
Como se explica en el índice de la página las redes neuronales se basan en la neuronas del cerebro humano. Una neurona esta interconectada con otras neuronas y responde cuando recibe un estimulo eléctrico. Cuando lo recibe decide si tiene que activarse o no. Si se activa, esa neurona enviará un impulso eléctrico a las neuronas que esta conectada. Si no se activa, no enviará información.
Las redes neuronales lo que hacer es seguir el mismo principio.
En el siguiente ejemplo basíco de funcionamiento de una red neuronal:
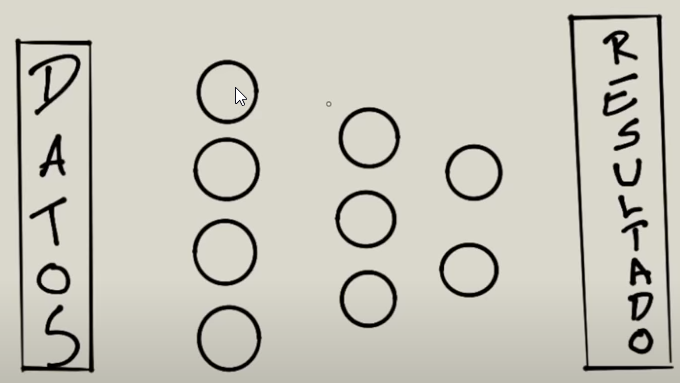
Es una diagrama que tienes tres capas:
- La capa que esta la izquierda del todo es la que recibe los datos. Será la capa que reciba los datos de entrenamiento.
- Laa capa que esta al derecha del todo es la que devuelve los resultados. Es la que recibe los datos de las capas ocultas y a partir de esos datos da un resultado.
- La capa en medio de ambas es la oculta, aunque en ejemplo solo hay una puede haber miles pero seguirán siendo la capa oculta. Serán las capas ocultas las encargadas de realizar todo el aprendizaje.
Las neuronas de las capaz se conectan a las neuronas de la siguiente capa tal como se en la siguiente imagen:
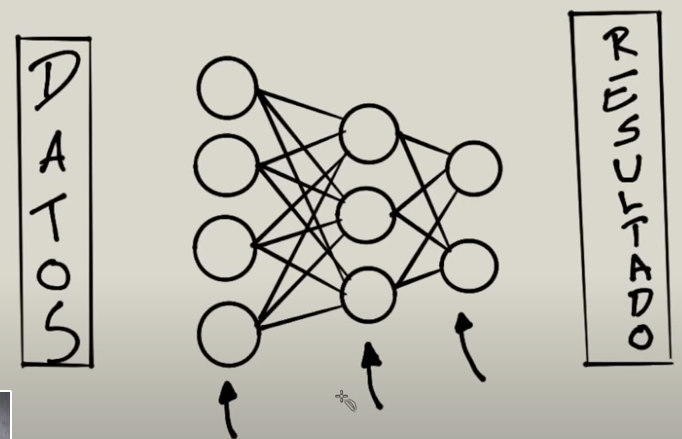
El proceso de entrenamiento es un proceso que irá enviando datos al algoritmo, este lo procesará y arrojará un resultado. Si el resultado contiene errores se ajustará los parámetros y se volverá a empezar. Si no hay errores entonces el algoritmo irá bien.
El funciona a nivel de neurona se puede ver en la siguiente imagen
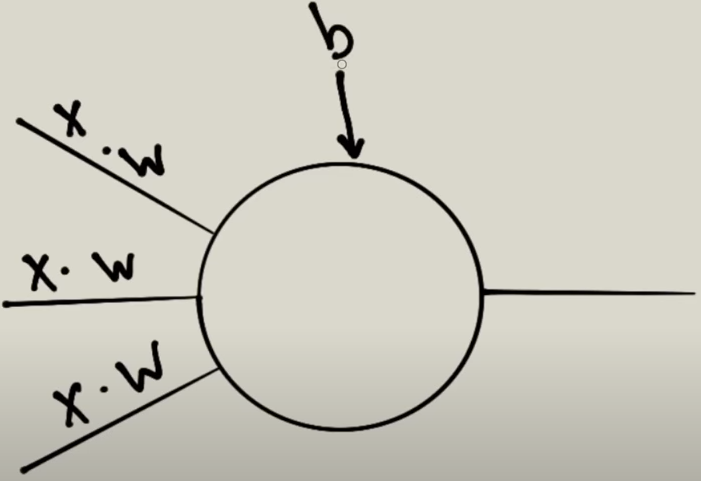
Una neurona recibe de otras neuronas lo siguientes datos:
- x –> Es valor a clasificar
- w –> El peso de ese valor. El peso permite es que dar más importancia a una conexión que a otra. Es decir, si tenemos X=4 y w=30 y también recibe x=3 y w=40. Tendrá más importancia el valor de x=3.
La neurona también tiene a nivel el valor b. b es el sesgo o bias(ingles). El sesgo indicará con que facilidad se activa la neurona sobre otras.
Para que una neurona se active y envie información a otra debe cumplirse una formula de activación que es la siguiente:
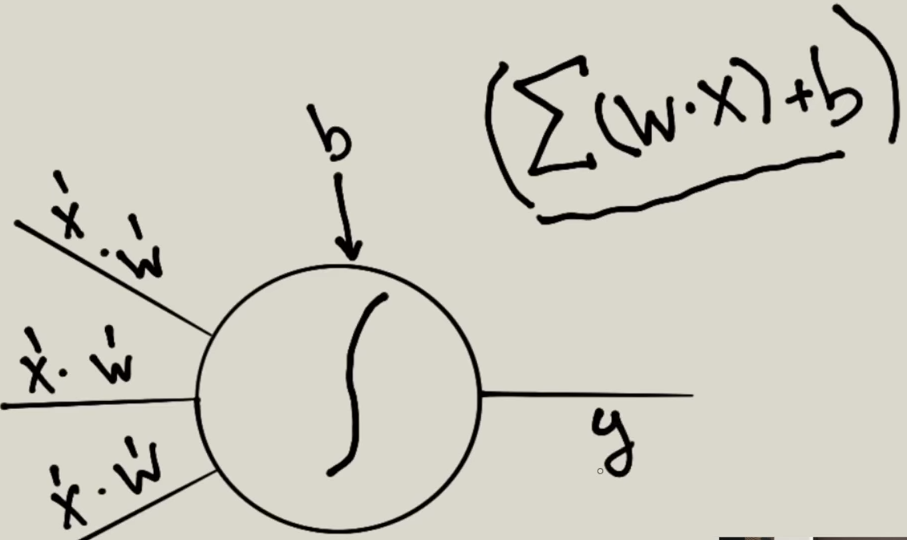
En esta formula se hace el sumatario de (valor * Peso) y al resultado se le suma el sesgo, el resultado se guarda en la variable y. Es el valor de esta variable si supera cierto valor entonces la neurona se activará y enviará el valor y, que será el valor x de entrada de la siguientes neuronas que esta conectada.
El proceso de entrenamiento es un proceso repetitivo donde se va repitiendo hasta que el resultado sea el esperado. En caso de volverse a repetir se ajustarán los valor de w y b. Para saber como de grande es el error se usará esta ecuación:
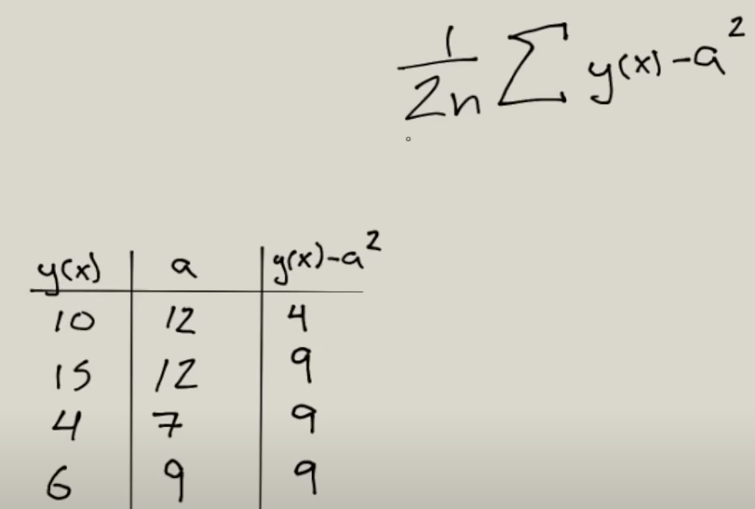
La ecuación se llama Error cuadrático medio, según entiendo del video.
En esta formulario se hace el sumario de y(es el resultado que devuelve la neurona) menos a, valor que se espera, elevado al cuadrado. El resultado lo vamos a multiplicar por 1/2*n. Donde n es el número de elementos que se le mando a entrenar.
Debajo hay una tabla donde tenemos el valor que devuelve, el valor que se espera y el resultado de la formula. El resultado de todos los valores es de 31. Este resultado se le aplicaría la siguiente formula: 31 * ( 1 / 2*n ). n en este caso es 4, porque son los valores que se le ha pasado para el entrenamiento, las filas de la tabla. Al final la formula sería 31 * (1/8) = 3,87. 3,87 es el error que se obtiene.
Ahora que sabemos el error en la siguiente iteracción hay que cambiar el valor de w y/o b para que el error se reduzca.
Para reducirlo se va utilizar el algoritmo gradiente descendiente
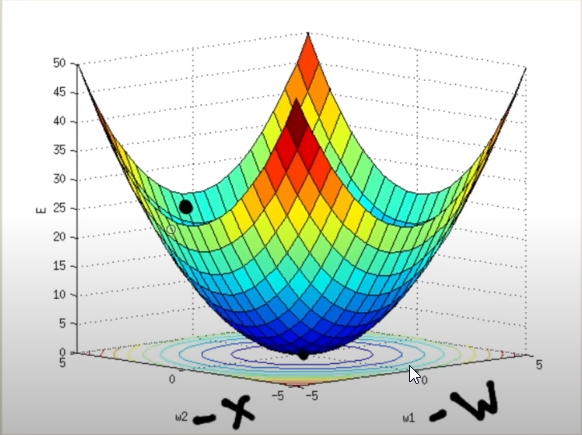
En este diagrama tenemos 3 ejes:
- w2 –> Es el equivalente a b, sesgo.
- w1 –> Es el equivalente a w, peso
- e –> Es el error que devuelve la formuala Error cuadrático medio
**NOTA: El video indica que modifica “x” pero no es correcto porque el valor de entrada no se modifica.
Donde se quiere llegar es hasta el punto más bajo donde el error esta minimizado.
El punto negro de la imagen supongamos que es donde esta el valor e que se ha obtenido en la formula. Ahora la formula, o algoritmo, va a derivar en ese punto la pendiente. Con el valor de la pendiente el algoritmo sabe donde se tiene que mover para llegar al mínimo global. Para ello irá ajustando los valores de b y/o w y relanzar de nuevo toda la red neuronal para comprobar el error que da.
Una vez que se llega al mínimo de error, la red ya esta entrada. En ese momento se le puede volver a pasar más datos pero ya no volverá a realizar ecuaciones cuadráticas ni grandientes descendientes porque cada elemento de la red ya tiene su valor de peso, w y b en cada neurona.
Cuando se entrena una red nosotros indicamos el número de iteraciones tiene. Esas iteracciones son las que se aplicarán la ecuación de error y gradientes descendiente. Si las iteracciones son bajas la corrección de error será baja y no hará buenas clasificaciones. Y si tenemos un número de iteracciones muy alto se corre el riesgo de sobreajuste. Con lo cual hay que ir cambiando el número de iteracciones, número de capas, etc. para ir ajustando los valores. Es decir, ir haciendo ensayo y error.
